区分一个测评工具和流程是否优秀和普通的方法很多,这在人才测评的领域是一个比较深的专业技术,考虑到广大的HR工作中不是做研究的,只要能在日常工作中掌握对测评工具的评价标准,区分工具的优劣就够了。因此跟大家分享三个最为关键的测评工具评价指标:信度、效度和常模,和猎萝卜小编一起了解。

1)信效度:测得稳和测得准
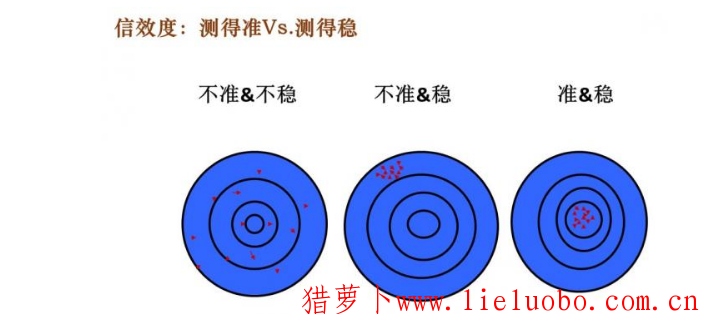
首先,我们来看一下信效度的基本定义。
信度指的是测量的稳定性、可靠性和一致性,效度指的是测量的准确性和有效性。通俗地说,信效度就是看一些测评能否做到测得准和测得稳,不,顺序对比颠倒了,测得稳和测得准。
正常的一个测评流程跑完,其信度与效度应该在0.7以上。如果某家公司说他测评工具的信度与效度在0.95以上,那一定是骗人的,因为人才测评不是物理测量,根本达不到如此高的信度与效度。
信度可以细分为内部一致性信度和重测信度。
• 内部一致性信度:指测验内部所有题目间的一致性程度,是测评编制时主要的信度资料。用TCC的测评工具做例子,第一,各测评工具均严格遵照心理学测评编制方法制成,因素分析法数学模型验证表明各维度对分测评总变异的解释均在71%以上;第二,TCC采用分半法对各分测评内部一致性进行验证,各分测评得分分布在0.78~0.94。
• 重测信度:定义很直白,就是再次测量的稳定性。对TCC三期微课学员跟踪200人进行重测,各测评间隔2周、10周的平均重测信度分别为0.86、0.69。说明测评稳定性相当好,测评得分的确反映了人格特质。
效度又可以细分为构想效度、内容效度、效标关联效度等。
• 构想效度和内容效度比较容易检测,构想效度指测验能够测量到理论上的构想或特质的程度、内容效度是指测验题目对有关内容或行为取样的准确性,特别是心理学的测评,更需要经得起研究验证,因此,TCC胜任力测评就是在国际心理学大师的理论基础上进行中国本土化研究并开发成中国管理者能理解的行为化测评语言。这就是理论效度和内容效度。
• 效标关联效度:指的是测评分数与效标结果之间关联的效度,根据效标结果与测评分数收集的时间,效标效度又可以分为同时效度和预测效度。TCC以企业内部主管能力评价或人才盘点结果作为效标,通过对厦门建发、TCL多媒体、江苏恒科、友和道通、深粮集团等多家企业累计500人以上的测评结果对比分析,最终企业内部评定为高能力者与测评结果中高能力者,命中率高达85%。
• 预测效度:这个是企业最为关心的,用测评结果预测胜任度和最终绩效的有效程度。预测效度越高,对组织的实践帮助越大。通过对友和集团300名招聘候选人进行跟踪研究,发现通过TCC测评报告评估为优秀者,入职半年后绩效为优秀者占比70%。
也有一个同样相反的案例,我的一位曾经的下属,现在为中国最大的财富管理公司诺亚集团高级HR总监负责招聘工作,他曾经根据针对公司的理财经理做了素质模型,并定制了某一家知名企业的素质测评,然后在过后半年多的时间,对比追踪了入职人员的绩效数据,如离职率、产单效率、人均收益等KPI指标,并没有发现统计意义上的显著差异,由此得出结论说这个测评工具的预测效度并不理想。
2)常模:测评数据的对比范围
人才测评在应用之前,需要施测一定的人群,将得到的分数加以统计整理,得出一个具有代表性的分数分布——这就是常模。测验得分必须与某种标准(也就是这里说的常模)比较,才能显示出它所代表的意义。

人才测评在应用之前,需要施测一定的人群,将得到的分数加以统计整理,得出一个具有代表性的分数分布——这就是常模。测验得分必须与某种标准(也就是这里说的常模)比较,才能显示出它所代表的意义。
如果一套测评系统没有常模,或者常模人群与自己的应用范围不符,建议不要选用。了解常模的方法有一定难度,通常通过了解常模的覆盖人群特点、人数规模、常模取样时间等来判断。
举例来说,一个人的测评数据如果跟北上广深的人群对比,就和二三线城市的数据对比有差异;如果拿总监、经理以上层级人群作为常模对比,就和一般人员的数据对比有差异;如果拿本企业的数据作为常模对比,就和全行业的人群数据对比有差异……
所以,一个优秀的测评工具,一定会特别注意自己的后台常模数据库的管理,不会轻易选取一些随随便便的数据入库作为常模对比使用。像我们TCC就特别注意控制测评人群的质量,选取的都是企业内一定经验和阅历的人群,并且能够区分后台管理。
当然,在实际操作中,有时候并没有特别适合本公司的常模数据,更多时候,测评的数据是可以自己对比、自己的企业内部数据对比。




